- Published on
Continuous forecasting with MLops pipeline on Kubernetes using Argo workflows, Influx and Darts
- Authors

- Name
- Peter Peerdeman
- @peterpeerdeman
The blog series about collecting timeseries, making predictions and making these predictions configurable is now coming to an epic conclusion where we all the previous steps and add a workflow engine to create a proper Machine Learning Operations (MLOps) pipeline, that automates all of the previous steps and runs every x amount of time.
If you are just tuning in, check the previous timeseries and forecasting blogs here:
- Using influxdb, grafana and nodejs datalogger rasplogger to visualise solar panel data
- Predicting timeseries data using Facebook Prophet in a Python Flask service, Influxdb and Grafana on Raspberry Pi
- Using Darts-Timeseries-Forecaster to perform configurable forecasting on timeseries
Now that we have finally prepared the proper Extract Transform Load (ETL) steps to create a single forecast for a timeseries in the previous blog using darts-timeseries-forecaster, we can now turn these steps into a workflow to be run on a kubernetes cluster.
The end goal of this project is to deploy an open source MLOps system that runs the workload in such way that we can:
- Configure multiple recurring forecasting jobs without making code changes
- Define the interval at which the forecasts are being refreshed
- Run on kubernetes, allowing us to scale the underlying infrastructure in case the workloads get bigger / need more compute.
This is where Argo Workflows comes in, an open source container-native workflow engine for orchestrating parallel jobs on Kubernetes. What I like about Argo is that all steps are defined in one flow, that all separate steps have their own docker containers and volumes can be shared between steps to avoid storing and loading data multiple times in between steps.
We get started by installing Argo Workflows and configuring access to the UI. You can read the detailed step by step process in my Installing Argo Workflows with ui access explained step by step blog.
Now we are ready to define our Argo Cron Workflow file. It is very similar to a normal Argo workflow, we just add some metadata to define the frequency at which the job should run. The final workflow will looks like this, I'll go into some details afterwards. you can also view the source on github:
apiVersion: argoproj.io/v1alpha1
#kind: Workflow
kind: CronWorkflow
metadata:
generateName: timeseries-prediction-parking-
namespace: argo
labels:
workflows.argoproj.io/archive-strategy: "always"
annotations:
workflows.argoproj.io/description: |
Fetching data from influx, predicting, storing it back to influx
spec:
schedule: "0 */12 * * *"
concurrencyPolicy: "Replace"
startingDeadlineSeconds: 0
successfulJobsHistoryLimit: 1
failedJobsHistoryLimit: 3
workflowSpec:
entrypoint: parking-prediction
volumeClaimGC:
strategy: OnWorkflowCompletion
volumeClaimTemplates: # define volume, same syntax as k8s Pod spec
- metadata:
name: timeseries-prediction-workdir # name of volume claim
spec:
accessModes: [ "ReadWriteOnce" ]
storageClassName: "local-path"
resources:
requests:
storage: 100Mi
templates:
- name: parking-prediction
steps:
- - name: extract-csv-from-influx
template: curl-query
arguments:
parameters:
- name: cmd
value: >-
curl -G 'http://192.168.1.5:8086/query'
--data-urlencode "db=parking"
--data-urlencode "q=SELECT mean(spaces) as value FROM \"parkingplace\" WHERE (\"name\" = 'P+R Noord' AND \"spaces\" != 0 ) group by time(10m) order by time desc limit 4038"
-H "Accept: application/csv" > /volume/parkingplace.csv
- - name: transform-darts-forecast
template: darts-timeseries-forecaster
- - name: load-predictions-into-influx
template: curl-query
arguments:
parameters:
- name: cmd
value: >-
curl -i -XPOST 'http://192.168.1.5:8086/write?db=parking' --data-binary @/volume/prediction.txt
- name: curl-query
inputs:
parameters:
- name: cmd
container:
image: curlimages/curl:latest
command: ["/bin/sh", "-c"]
args: ["{{inputs.parameters.cmd}}"]
volumeMounts: # same syntax as k8s Pod spec
- name: timeseries-prediction-workdir
mountPath: /volume
- name: darts-timeseries-forecaster
container:
image: peterpeerdeman/darts-timeseries-forecaster:latest
command: ["python", "app.py"]
env:
- name: INPUT_FREQUENCY
value: 10min
- name: INPUT_FILENAME
value: /volume/parkingplace.csv
- name: INPUT_MOVINGAVERAGE
value: '30'
- name: PREDICTION_SPLIT
value: '0.75'
- name: OUTPUT_FORMAT
value: influx
- name: OUTPUT_FILENAME
value: /volume/prediction.txt
volumeMounts: # same syntax as k8s Pod spec
- name: timeseries-prediction-workdir
mountPath: /volume
The cron workflow file can be submitted through the ui interface, or use the command line argo tool: argo cron create timeseries-prediction-parking.yaml
I'll go through some of the highlights in the workflow:
Config
- the
generateNameis the prefix of the podname, I end with a '-' because a small id will be added afterwards - the
scheduleis the typical cron notation for how often the job should run, use crontab.guru to find the right value - the
successfulJobsHistoryLimitandfailedJobsHistoryLimithave saved me from completly flooding the pod view in k9s - the
entrypointshould refer the first step that should be run in the flow
Persistence
- the flow creates a volume claim that can later be mounted in any of the steps, in this example you can see both the curl-query step and the darts-timeseries-forecaster steps mount the volume
Steps vs Templates
- in this workflow I define two step templates, one is curl-query and one is darts-timeseries-forecaster.
- The steps define the actual work that gets done, the templates offer a way to reuse some of the step configuration.
Forecasting Workflow Steps
- The first step performs the curl query we defined in the previous blog, and stores the result in the attached volume
- the second step runs the forecaster image, and is configured to consume the csv data from the attached volume and writes back the influx lines to a text file.
- the final step POST's the influx lines back to influxdb
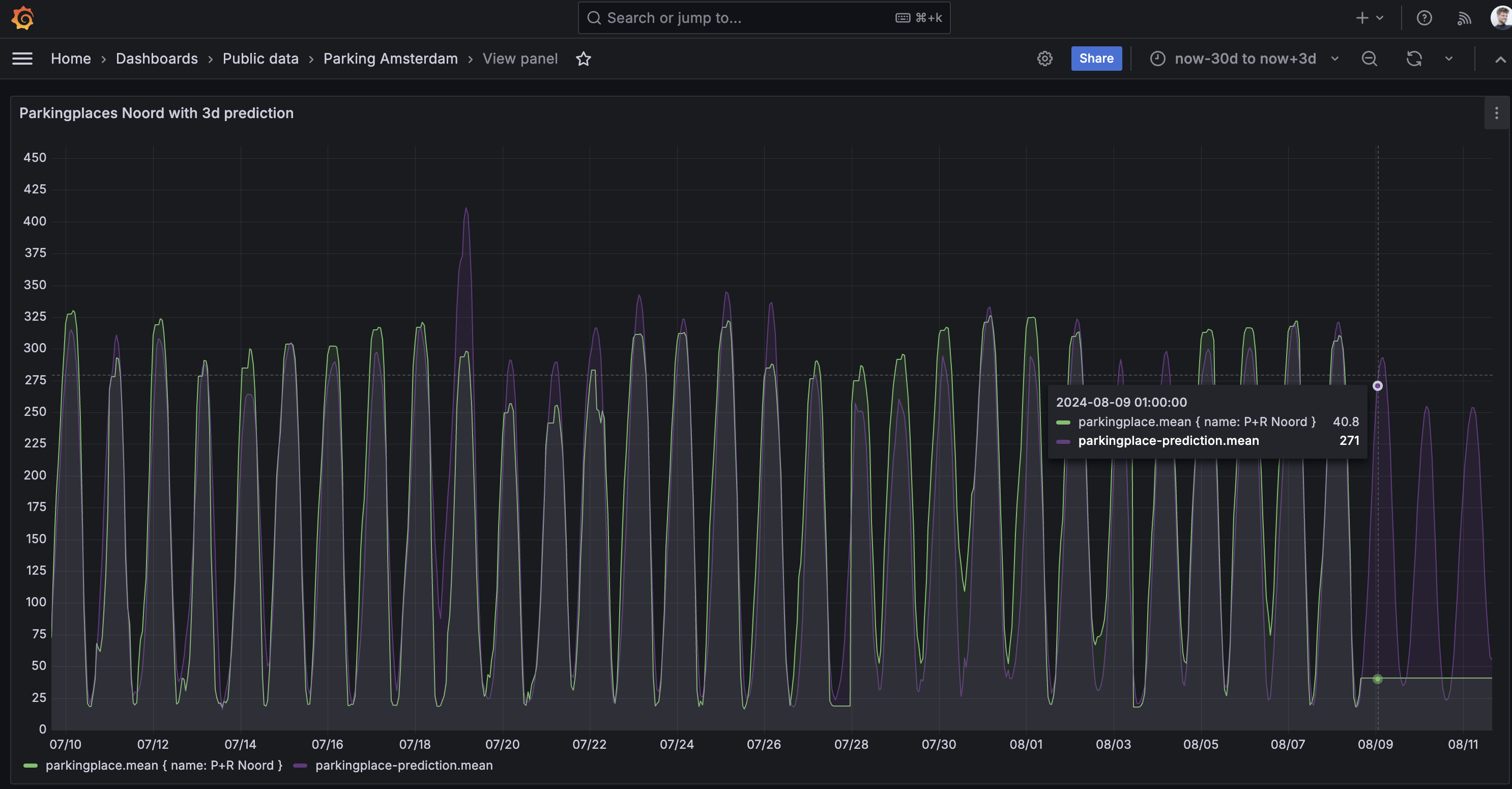
Conclusion
After running the prediction pipeline, we can now view the prediction in grafana by extending the timeframe to include future values. If you want to create forecasts for other timeseries, you can create a new workflow, modify the query and forecasting parameters and run as many cron workflows as you like. And if the jobs get heavier, you can add nodes to the cluster and even use the node selector to let certain steps only run on more powerful or GPU/TPU enabled nodes!