- Published on
Fixing Longhorn instance manager max CPU issues
- Authors

- Name
- Peter Peerdeman
- @peterpeerdeman
I've been running a longhorn installation on a raspberry pi cluster for a while now. After some time, I started noticing the control plane becoming unstable and going offline, effectively making the workloads on the cluster inaccessible.
After rebooting the node, the cluster would come online and then become unreachable after about 20 to 30 minutes. After rebooting and immediately SSH'ing in I found that the pod "longhorn instance-manager" was running a process with 250% CPU, slowly grinding the poor raspberry pi to a halt.
If I would kill the pod, the CPU would go back down, but of course kubernetes would detect this, recreate the instance manager pod and the CPU problem would re-appear. Inspecting the logs of the instance manager, I found no noticable clues other than an update watch running:
(base) » k logs instance-manager-52c9b80bf492c0e68c6d3174b98e0044 -n longhorn-system [±master ●●]
...
[longhorn-instance-manager] time="2024-05-08T12:52:02Z" level=info msg="Start watching processes" func="instance.(*Server).watchProcess" file="instance.go:621"
[longhorn-instance-manager] time="2024-05-08T12:52:02Z" level=info msg="Start handling notify" func="instance.(*Server).handleNotify" file="instance.go:451"
[longhorn-instance-manager] time="2024-05-08T12:52:02Z" level=info msg="Started new process manager update watch" func="process.(*Manager).ProcessWatch" file="process_manager.go:377"
Because It was only the control plan having these issues, I continued to find out if I could decrease the activity on the control plane through the longhorn ui.
Using the port forward kubectl port-forward --namespace longhorn-system svc/longhorn-frontend :80 I changed the amount of replicas on the volumes to 1, effectively eliminating the need for the cluster to do anything, but the problem still persisted.
It was only after I used the longhorn ui to disable node scheduling and requested eviction for the control plane that the troublesome process went away.
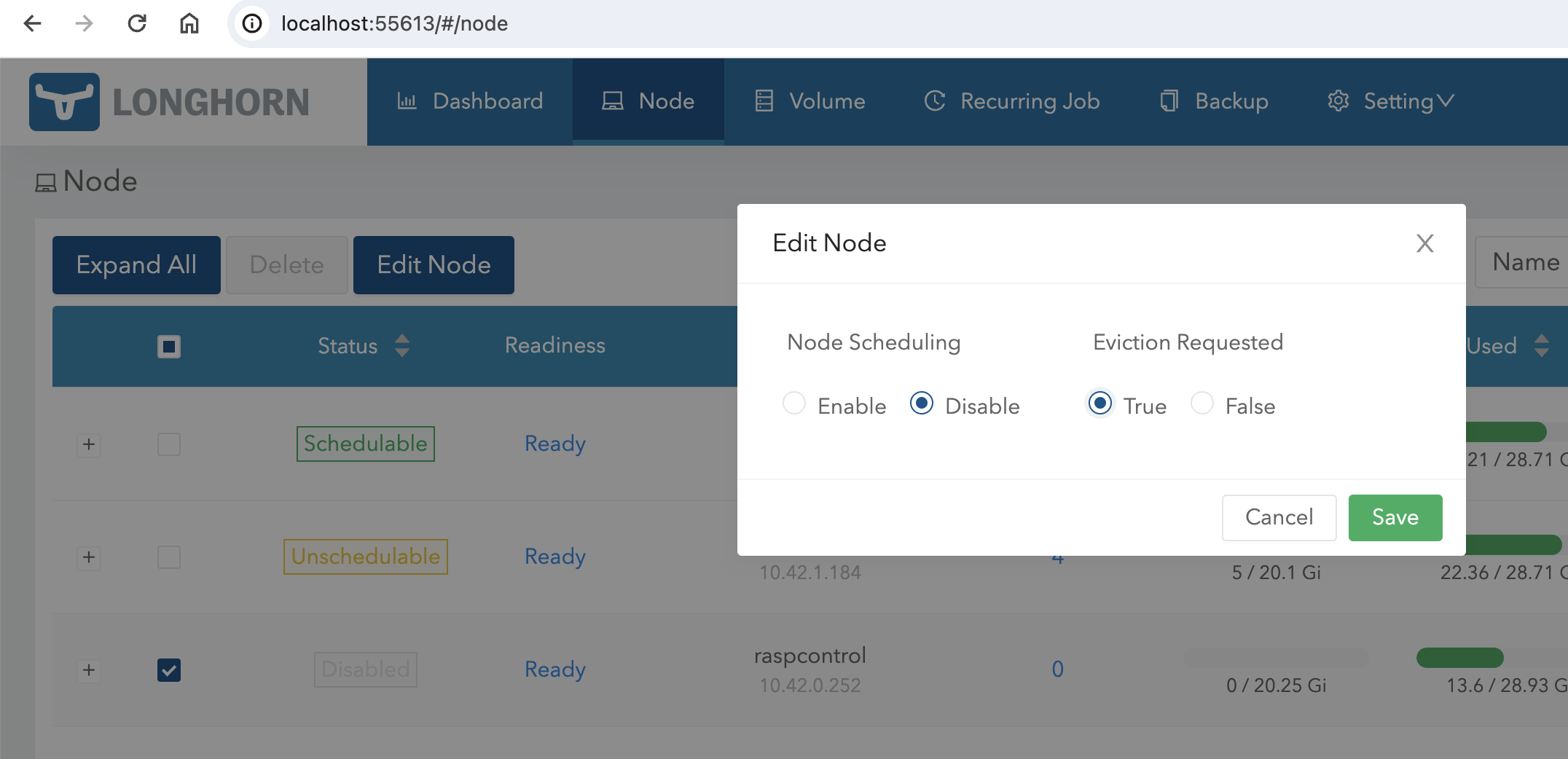
As I didn't figure out the exact reason for the problem, my takeaway from this issue is to keep the workloads on the control plane as light as possible, and to not use the controlplane as a part of the replicated storage solution. Any problems on the control plane node have direct effect on the stability of the whole cluster.