- Published on
Building recordfairs.nl, a webscraper application in nodejs with postgres database
- Authors

- Name
- Peter Peerdeman
- @peterpeerdeman
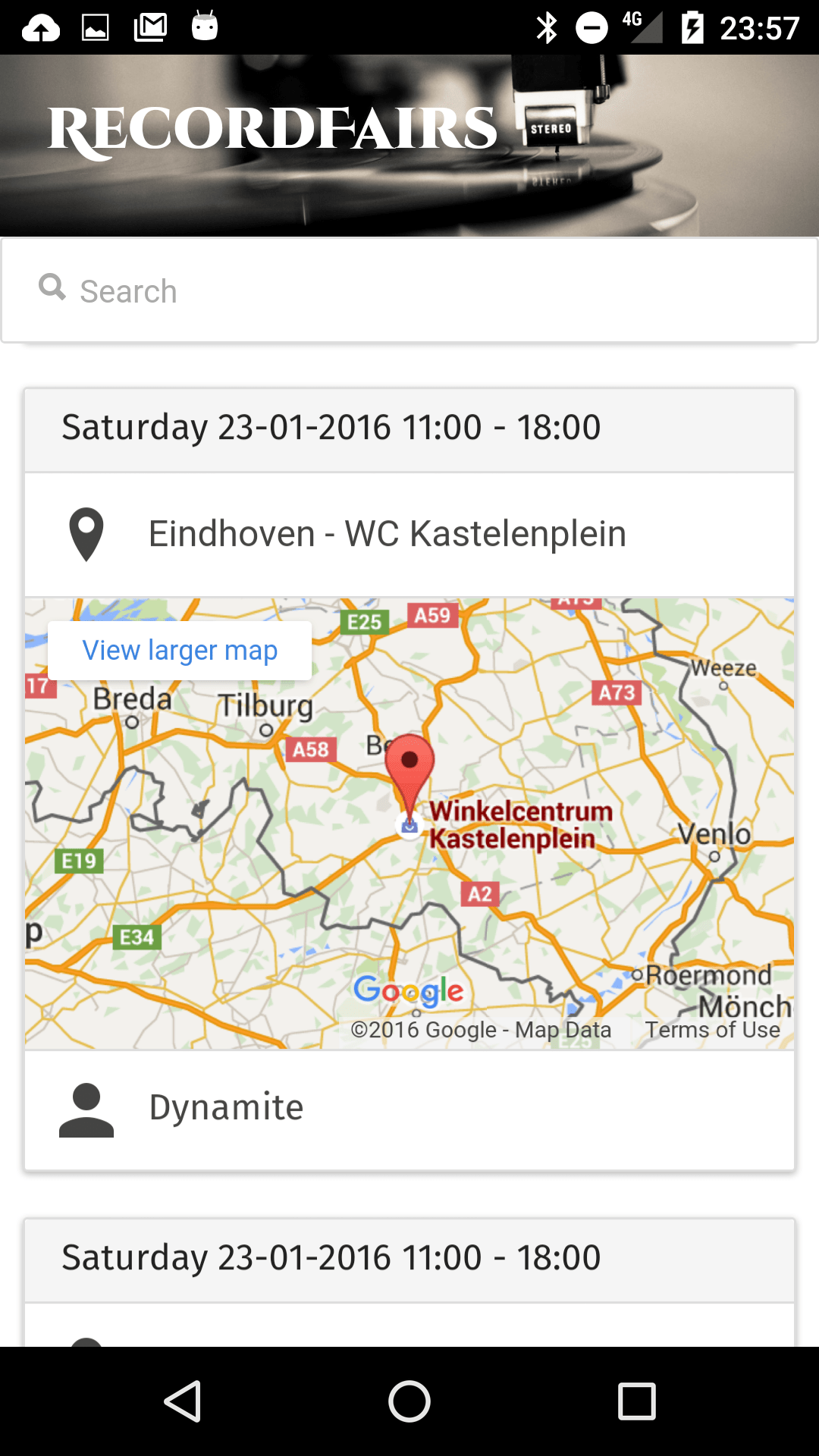
As I've begun with a modest vinyl collection hobby I've been visiting some local recordfairs. While searching for them online I have found numerous websites from different labels / brands / stores that list upcoming record fairs. After wading through all the different sites for a third time I thought: "wouldn't it be great if there was just one big aggregated table of all these recordfairs in a nice and simple mobile friendly layout?" and with that, the idea of recordfairs.nl was born.
As I wanted the operational costs to be as low as possible, I've decided to host recordfairs on heroku using the free plan. I'm glad I was able to use nodejs and for the free database plan I had to use PostgreSQL. For the node part I generated a project using the express-generator, opted for some jade templates, used sequelize models for postgres integration and the ever-so-amazing cheerio for scraping the different websites with the data. The front-end is basic bootstrap with a header image of a recordplayer that I shot a while ago.
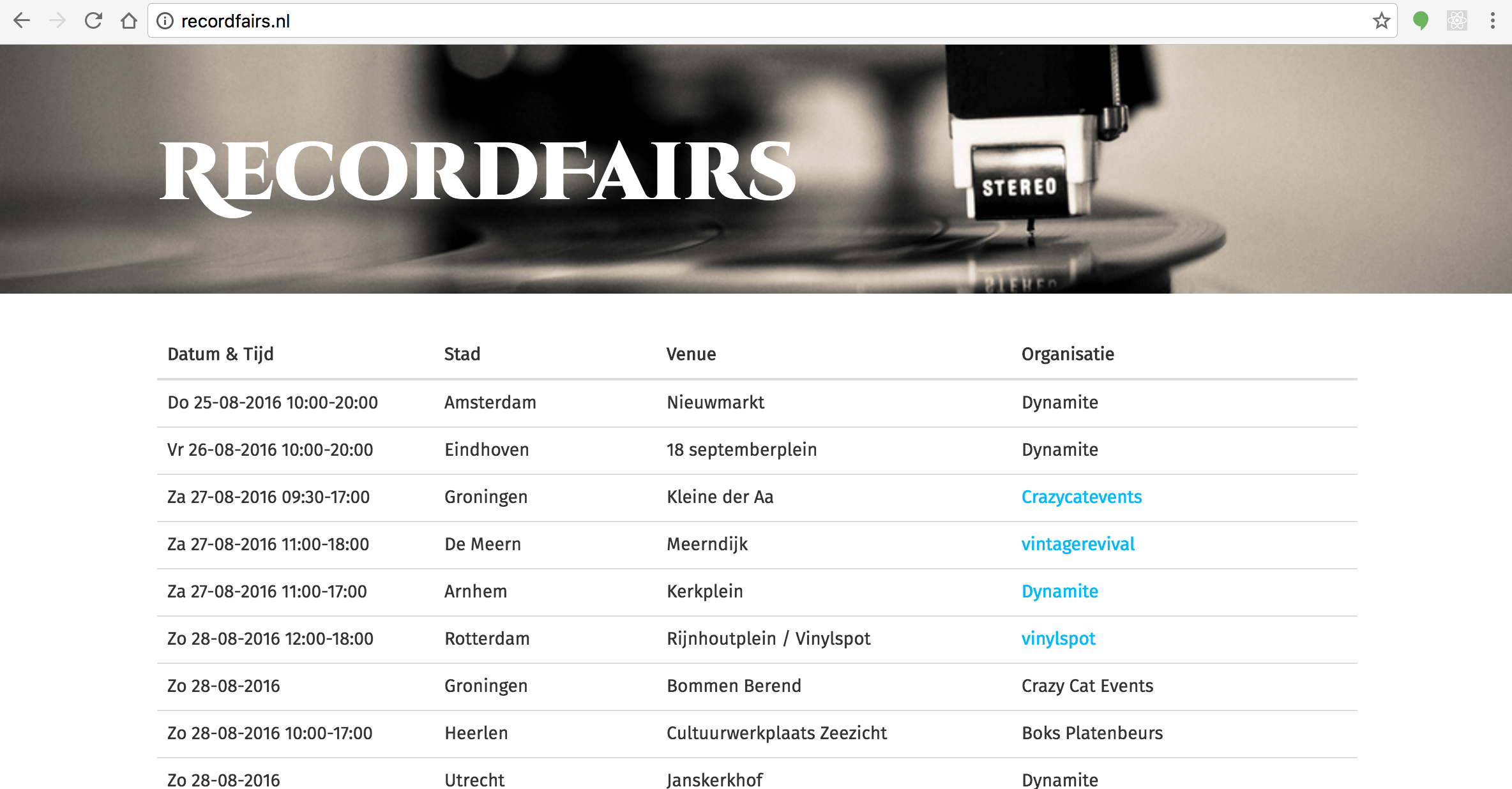
As you might have expected, scraping the data, getting into a unified format and avoiding duplicate entries in the database was the most exciting part of this application. Especially the dates, for they were in different text formats on almost each of the sites, some even just listing the starting time and finishing time as hours with 2 digits.
The request-promise npm package was a great help to help make scraping the sites asynchronous and chain them all together. Each of the scrapers exposes a promise:
'use strict';
let cheerio = require('cheerio');
let S = require('string');
let moment = require('moment');
let rp = require('request-promise');
let Promise = require('bluebird');
let debug = require('debug')('myappdebugtag');
module.exports = function () {
var options = {
uri: 'http://scrapesource',
transform: function (body) {
return cheerio.load(body);
},
};
return rp(options)
.then(function ($) {
let dataTable = $('table').first();
return dataTable
.find('tbody tr')
.toArray()
.map(function (el) {
let row = $(el);
let dateInput = S(row.find('td:nth-child(2)').text()).trim().s;
if (!dateInput) return null;
let date = moment(dateInput, 'D-MMM', 'nl');
let timeInput = S(row.find('td:nth-child(6)').text()).trim().s;
let times = timeInput.split('-');
let startDate;
let endDate;
if (timeInput && times.length > 0) {
let startTimeString =
times[0].indexOf('.') > 0
? times[0].replace('.', ':')
: times[0] + ':00';
let endTimeString =
times[1].indexOf('.') > 0
? times[1].replace('.', ':')
: times[1] + ':00';
startDate = moment(
`${date.format('MM-DD-YYYY')} ${startTimeString}`,
'MM-DD-YYYY HH:mm'
).toDate();
endDate = moment(
`${date.format('MM-DD-YYYY')} ${endTimeString}`,
'MM-DD-YYYY HH:mm'
).toDate();
}
let fair = {
date: date.toDate(),
startDate: startDate,
endDate: endDate,
city: row.find('td:nth-child(3)').text(),
country: row.find('td:nth-child(4)').text(),
location: S(row.find('td:nth-child(5)').text()).trim().s,
organiser: row.find('td:nth-child(7)').text(),
origin: 'scrapesource',
};
return fair;
});
})
.catch(function (err) {
console.log(err);
});
};
I created an endpoint that initiates the scraping process, which imports and executes the above promise calls, and handles the resulting data in the then handler. Just before storing the data in the database, I check if there is already a fair for that date and city:
function handleFairs(fairs) {
fairs.forEach(function (fair) {
if (!fair) {
return;
}
models.Fair.findOne({
where: {
date: fair.date,
city: fair.city,
},
}).then(function (existingFair) {
if (existingFair) {
console.log('existing found', existingFair.id);
} else {
models.Fair.create(fair)
.then(() => {
console.log('added fair', fair.city, fair.date);
})
.catch((err) => {
console.log('an error occurred');
});
}
});
});
}
Pretty straightforward, but a fun experience nonetheless. As you can see on recordfairs.nl, the result isn't perfect but it's still a lot better than visiting all of the urls separately. As a small addition, I've also created a small cordova app for android using ionic that basically displays the same information and allows you to do a clientside search through the retrieved data, check it out for free: Record Fairs on the android playstore